












World Record 969 Tokens per Second is up to 75 times Faster than GPUs Offered by Hyperscalers
Cerebras Systems today announced that it has set a new performance record for Llama 3.1 405B – a leading frontier model released by Meta AI. Cerebras Inference generated 969 output tokens per second. Data from third party benchmark firm Artificial Analysis shows Cerebras up to 75 times faster than GPU based offerings from hyperscalers. Cerebras Inference is running multiple customer workloads on Llama’s 405B model at 128K full context length and 16-bit precision.
This press release features multimedia. View the full release here: https://www.businesswire.com/news/home/20241118828747/en/
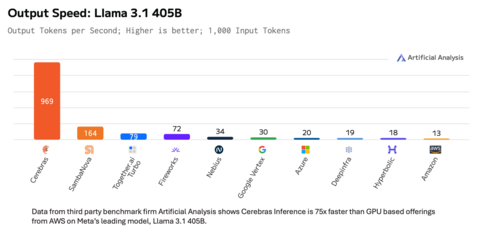
Data from third party benchmark firm Artificial Analysis shows Cerebras Inference is 75x faster than GPU based offerings from AWS on Meta's leading model, Llama 3.1 405B. (*data from 11/14/2024) (Graphic: Cerebras Systems)
Not only was Cerebras’s performance nearly two orders of magnitude faster than the leading GPU offerings from hyperscalers, but the time to first token, the definitive measure of latency and user experience, was the fastest measured in the world at 240 milliseconds – a fraction of leading GPU clouds.
These breakthroughs represent a significant milestone in AI inference capabilities, enabling instant responses from large language models that typically require several seconds to generate outputs. For the first time, the largest of language models has real time performance and this is only available on Cerebras.
“Scaling inference is critical for accelerating AI and open source innovation. Thanks to the incredible work of the Cerebras team, Llama 3.1 405B is now the world’s fastest frontier model running at a rapid-fire pace of 969 tokens/sec. Through the power of Llama and our open approach, super fast and affordable inference is now in reach for more developers than ever before. We are thrilled to support Cerebras’s latest breakthrough as they continue to push the boundaries in compute for AI,” said Ahmad Al-Dahle, GenAI VP at Meta.
“Today, we enabled one of the largest models in the world -- one of a few select frontier models -- to achieve instant performance,” said Andrew Feldman, co-founder and CEO of Cerebras. “Cerebras holds the world record in Llama 3.1 8B and 70B performance, and with today’s announcement, we're extending our lead to Llama 3.1 405B – delivering 969 tokens per second. By running the largest models at instant speed, Cerebras enables real-time responses from the world’s leading open frontier model. This opens up powerful new use cases, including reasoning and multi-agent collaboration, across the AI landscape.”
As recent work by OpenAI and others has shown, greater inference compute directly translates into greater model accuracy and capability. Traditional LLMs print out their answers without deliberation or reflection, often resulting in incorrect responses for complex problems. Run time techniques that use search and chain-of-thought reasoning, on the other hand, explore different possibilities and provide the best possible answer. This "think before answering" approach provides dramatically better performance on demanding tasks like math, science, and code generation, fundamentally boosting the intelligence of AI models without additional training. By running up to 75x faster than GPU solutions, Cerebras Inference allows AI models to "think" far longer and return more accurate results.
Cerebras Inference is powered by the Cerebras CS-3 system and its industry-leading AI processor, the Wafer Scale Engine 3 (WSE-3). Unlike graphics processing units that force customers to make trade-offs between speed and capacity, the CS-3 delivers best-in-class per-user performance and the lowest latency while delivering high throughput. The massive size of the WSE-3 enables many concurrent users to benefit from blistering speed. With 7,000x more memory bandwidth than the Nvidia H100, the WSE-3 solves Generative AI's fundamental technical challenge: memory bandwidth. Developers can easily access the Cerebras Inference API, which is fully compatible with the OpenAI Chat Completions API, making migration seamless with just a few lines of code.
Availability
Cerebras Inference Llama 3.1 405B with context lengths up to 128K is in customer trials today with general availability in Q1 2025. It is offered at $6 dollars per million input tokens and $12 dollars per million output tokens.
Llama 3.1 8B and 70B are available as free and paid versions on our website.
To learn more visit: www.cerebras.ai.
About Cerebras Systems
Cerebras Systems is a team of pioneering computer architects, computer scientists, deep learning researchers, and engineers of all types. We have come together to accelerate generative AI by building from the ground up a new class of AI supercomputer. Our flagship product, the CS-3 system, is powered by the world's largest and fastest commercially available AI processor, our Wafer-Scale Engine-3. CS-3s are quickly and easily clustered together to make the largest AI supercomputers in the world, and make placing models on the supercomputers dead simple by avoiding the complexity of distributed computing. Cerebras Inference delivers breakthrough inference speeds, empowering customers to create cutting-edge AI applications. Leading corporations, research institutions, and governments use Cerebras solutions for the development of pathbreaking proprietary models, and to train open-source models with millions of downloads. Cerebras solutions are available through the Cerebras Cloud and on premise. For further information, visit www.cerebras.ai or follow us on LinkedIn or X.
View source version on businesswire.com: https://www.businesswire.com/news/home/20241118828747/en/
Contacts
Media Contact
Press Contact: PR@zmcommunications.com
